Data Migration and Integration




HackerRank’s North Star Goal
HackerRank wants to build a robust, scalable, and unified data infrastructure to support operational analytics and long-term data strategy. At the core of this vision is the seamless replication of production data from its relational databases, Amazon RDS and Aurora, into a modern cloud data warehouse environment powered by Snowflake.
To achieve this, they wanted to leverage Hevo Data as their primary data pipeline solution, which enables near real-time data ingestion with minimal engineering overhead. This will allow them to ensure that critical business data ranging from user activity to transactional records will be continuously available for analytics, reporting, and decision-making.
Beyond simply centralizing data in Snowflake, HackerRank wanted to implement a multi-destination data strategy. They wanted to maintain a complete and reliable copy of their data in Amazon S3 for cost-effective storage, backup, and archival purposes. At the same time, they wanted to replicate this data into Amazon Redshift to support additional analytical workloads and provide flexibility for different teams and use cases.
In essence, their North Star goal was not just be about data movement it was about building a resilient, future-proof data ecosystem that will ensure accessibility, redundancy, and performance across multiple platforms while minimizing operational complexity.
The Problem
HackerRank has built a high-scale developer assessment platform serving over 23 million developers and 3,000 enterprise customers. However, its data infrastructure did not keep pace with the product’s growth.
Production data was fragmented across Amazon RDS and Aurora PostgreSQL instances, along with a sprawl of Amazon S3 buckets. Each system operated in isolation, leaving no unified analytics layer. Engineering teams querying Amazon Redshift rely on data that lags hours behind production. Data science teams lack reliable access to clean, modeled datasets, while BI dashboards were built on inconsistent definitions without a single source of truth.
The core issue is not data volume, but fragmentation and latency. Redshift was being stretched to function as both an operational store and an analytics warehouse a dual role it increasingly was unable to sustain at scale. Schema drift between Aurora and Redshift went undetected. There was no transformation layer to enforce data contracts, no semantic layer to standardize metrics, and no governed path from raw production data to business intelligence.
As a result, product, customer success, and engineering teams were making decisions based on stale, inconsistent data. HackerRank needed a modern, governed, cloud-native data warehouse, along with a reliable pipeline to power it.
Evolution of HackerRank’s Stack with Analyze Agency
Analyze Agency worked collaboratively with HackerRank’s data engineering team to methodically break down the fragmentation, which was replaced by a modern, governed, end-to-end-data pipeline powered by Snowflake.
The team began deploying AWS Database Migration Service (DMS), choosing it as the replication backbone instead of building custom ETL tooling. Analyze Agency connected DMS directly to Aurora / RDS PostgreSQL instances using logical WAL-based CDC. An initial full load established a clean baseline in Amazon Redshift, after which the system transitioned to continuous CDC, capturing all INSERT, UPDATE, and DELETE operations from Aurora/RDS in near real time. Raw data files/rows landed in Amazon S3 and Redshift using parallel AWS Glue jobs and COPY commands ensuring no production data remained outside the consolidated layer.
Analyze Agency then introduced HevoData as the integration layer, with Redshift acting as the intermediate consolidation warehouse. Cross-domain pipelines were established for users, assessments, billing, and events, each configured with incremental watermarks and schema mappings to handle type differences between Redshift and Snowflake. From there, all data was loaded into Snowflake’s RAW layer, preserving full fidelity with no transformations applied at ingestion.
Transformation was orchestrated within Snowflake using dbt. Analyze Agency implemented a three-layer architecture namely raw, staging, and curated. Staging models handled cleansing, type casting, and deduplication, while mart models produced well-structured fact and dimension tables in a star schema. On top of the Curated layer, a semantic layer standardized metric definitions across domains, ensuring every downstream consumer operated from a single, governed source of truth.
The outcome was an integrated, continuously published, transformation driven Snowflake-based data platform.
Data Migration and Integration
HackerRank’s primary engineering challenge was to bring together highly fragmented production data into a single, governed analytics platform capable of serving the business in near real time. This required consolidating four critical data domains namely developer profiles, registration events, account metadata, and enterprise customer records. Each of these domains came with its own schema complexity, updation cadence, and downstream consumption patterns. Operational datasets like users and billing demanded high-fidelity change data capture to ensure no updates were missed, while high-volume domains such as assessments and events required efficient incremental loading strategies within Hevo Data to prevent overloading the warehouse.
The goal was to unify all of this within a curated layer in Snowflake, where data would be modeled into clean, well-structured star schema; fact tables capturing transactional activity and dimension tables providing consistent reference data. Using dbt, business logic and metric definitions were formalized into mart models, replacing previously inconsistent, team-specific interpretations. Success was clearly defined any analyst, data scientist, or API consumer querying the Snowflake curated layer would access data no more than 15 minutes behind production systems on Aurora, with zero schema drift and complete, traceable lineage managed through dbt.
Architecture
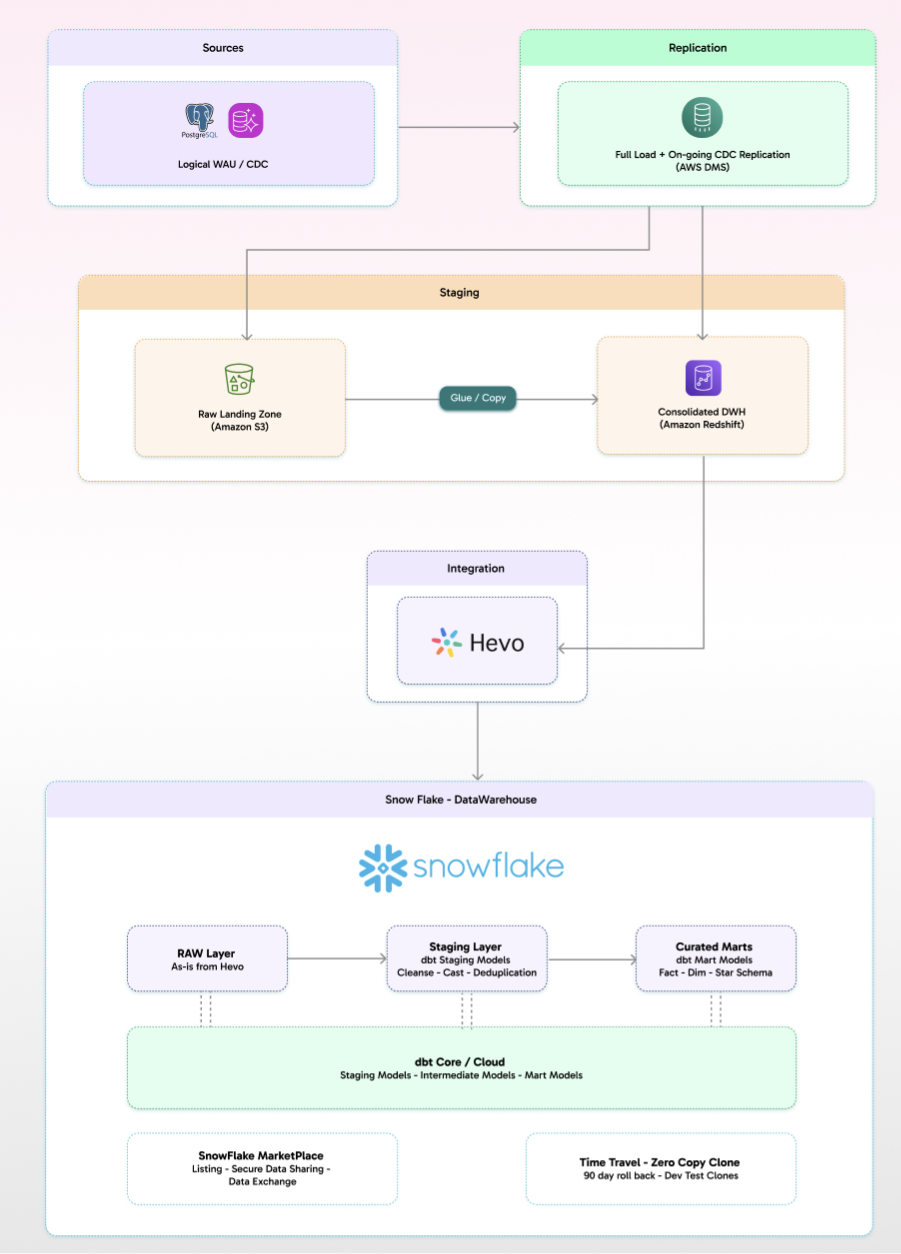
HackerRank’s data platform is built as a structured, multi-layer pipeline that moves data cleanly from production systems into a governed analytics environment. At the source, data originates from PostgreSQL-based systems , where change data capture is enabled through logical WAL, ensuring every transaction is captured at the database level. This stream is picked up by AWS Database Migration Service, which handles both the initial full load and continuous CDC, replicating changes downstream in near real time.
The data then lands in the staging layer, which is split across two systems. Amazon S3 acts as the raw landing zone, storing incoming data in its original form, while Amazon Redshift serves as a consolidated staging warehouse where data from multiple streams is brought together. Using Glue and COPY operations, data is efficiently moved from S3 into Redshift, forming a unified intermediate layer before further distribution.
From there, Hevo Data handles the integration into Snowflake, continuously syncing curated datasets across domains such as users, assessments, billing, and events with incremental loading and schema alignment. Inside Snowflake, the architecture follows a clear progression: data first lands unchanged in the RAW layer, then moves through staging models built with dbt for cleansing, casting, and deduplication, and finally into curated mart models structured as fact and dimension tables in a star schema.
This layered approach is reinforced by dbt’s modeling framework and Snowflake’s native capabilities like Marketplace data sharing, Time Travel, and zero-copy cloning, which support governance, recovery, and efficient development workflows. The end result is a clean, transformation-driven data platform where all downstream consumers including BI tools, data science workloads, and internal applications operate on consistent, well-modeled data from a single source of truth.
Evaluation & Outcomes
The shift to an AWS Database Migration Service-to-Snowflake architecture fundamentally transformed HackerRank’s data platform, giving teams access to a single, continuously updated analytical layer built on a governed source of truth. For the first time, data across the organization was no longer fragmented or delayed, but unified and readily available for decision-making.
Prior to this, Amazon Redshift had been stretched to serve as both an operational store and analytics warehouse, without a proper transformation layer to enforce data contracts or a semantic layer to align metric definitions. The introduction of Snowflake’s curated layer changed that. It provided product, customer success, and engineering teams with a near real-time, domain-oriented view of platform activity—spanning users, assessments, billing, and events—something that simply didn’t exist before.
From an architectural standpoint, the foundation proved solid. AWS DMS acted as the replication backbone, capturing changes from Aurora PostgreSQL via logical WAL-based CDC with consistently low replication lag. The transition from initial full loads to continuous CDC across all four domains was completed without data loss, establishing a reliable flow of production data into the pipeline.
Hevo Data addressed one of the more persistent issues—schema drift—through its schema mapping and domain-based pipeline configuration. Differences in data types and naming conventions between Redshift and Snowflake were normalized, while incremental watermarking ensured that high-volume tables, particularly in assessments and events, were ingested efficiently without overwhelming the system.
On top of this, dbt introduced a structured transformation layer that formalized the progression from RAW to Staging to Curated. This wasn’t just a modeling exercise—it established a tested, documented data contract. Fact and dimension tables in the curated layer became the definitive source for BI, data science, and API consumers, while dbt’s semantic layer finally standardized metric definitions across the business.
Most importantly, the architecture delivered on HackerRank’s North Star: reducing “time to trusted data.” Production events captured in Aurora were consistently available in Snowflake as clean, query-ready records within 15 minutes, enabling faster, more confident decision-making across the organization.
Future Priorities
With the Snowflake curated layer firmly in place as the analytical foundation, HackerRank’s next phase of data evolution focuses on deepening intelligence and expanding platform capabilities across three key areas.
First, the focus shifts to real-time scoring and personalization. By combining Snowflake’s native ML capabilities with transformations built in dbt, HackerRank can develop developer-level recommendation systems driven by assessment history, skill progression, and challenge completion patterns. These insights can then be fed back into the core platform to power personalized learning paths and more precise hiring recommendations.
Second, the existing architecture creates a strong foundation to expand into additional use cases without introducing new ingestion layers. The same pipelines and models can support advanced analytics such as developer churn prediction, enterprise customer health scoring, campaign attribution, and pricing optimization all running directly on the current Snowflake stack.
Finally, the platform can evolve toward a data mesh model, where ownership of dbt models is distributed across engineering, product, and customer success teams. With Snowflake’s data sharing capabilities enabling governed cross-domain access, and integrations like Snowflake Marketplace allowing third-party data enrichment, HackerRank can unlock broader insights such as talent market intelligence and benchmarking extending the value of the platform well beyond internal analytics.
Why Analyze Agency
Analyze Agency operates at the intersection of data engineering, analytics, and business intelligence building integrations that are not just technically robust but tightly aligned with business outcomes.
In the case of HackerRank, this approach turned four fragmented production data domains into a unified, Snowflake-native analytics platform. For the first time, teams across the organization gained access to a real-time, governed, and domain-aligned view of critical data spanning users, assessments, billing, and events.
We stay relentlessly focused on the outcome. Our goal is to create the most direct, efficient path from raw production data to business intelligence by minimizing friction, latency, and ambiguity along the way.
Our Success Framework
Analyzing a problem always starts with getting crystal clear on what’s actually broken. For HackerRank, the issue was obvious: their data was all over the place. Two separate PostgreSQL databases, an outdated Amazon Redshift cluster, scattered files in S3, and no single source of truth for anything whether it was user activity, assessments, billing, or events. It wasn’t just messy; it was holding them back.
Instead of jumping straight into fixes, we took a step back and mapped out the entire architecture first. AWS Database Migration Service became the backbone for change data capture (CDC), Redshift served as the staging area to pull everything together, and we designed a three-layer model in Snowflake before writing a single line of dbt. Every decision was made with a purpose: building something reliable, scalable, and actually useful.
The end result isn’t just a migration it’s a proper data platform. Every piece, from Aurora to Snowflake’s curated layer, has a clear role, an owner, and a set of rules for how data moves through it. We rolled it out in phases, checking at each step to make sure we were hitting the mark: faster, more reliable access to data people could trust.
Now, HackerRank doesn’t just have a cleaner setup. They’ve got a system they can grow with one that’s built to handle whatever comes next.
Get In Touch
If your organization is undergoing a data migration, modernizing a legacy warehouse, or building a governed analytics platform from the ground up, Analyze Agency can help. We bring deep expertise across AWS Database Migration Service, Hevo Data, Snowflake, and dbt with a proven track record of delivering architectures that are tightly aligned to your North Star, whether that’s real-time insights, data reliability, or faster decision-making.
If you’re trying to unify fragmented data sources, navigate compliance constraints, or evaluate the right approach between self-hosted, sovereign, or hybrid data architectures, you’re not alone. These are high-stakes decisions, and getting them right can define how effectively your business operates.
Reach out at Discovery@analyze.agency or book a consultation. We’ll help you cut through the noise, define a clear path forward, and design a solution that fits your business. Your next strategic move can start with a simple conversation.


Powered by Leading Technologies












What Our Client Says About Us
Analyze Agency transformed our Snowflake warehouse into a efficient data powerhouse.
NBC Team
.webp)
Analyze Agency ‘s team was great to work with and helped us tremendously in gathering relevant data for our clients. We enjoyed working with him and would definitely recommend them.
Hackers Rank Team

Excellent data scientists. Will work with them again in the future.
Moneylion Team

Expert, quick pace, practical.
Upwork Team

The team continually repointed us to focusing on results. They dug into the analysis quickly, understood the context of our business, and worked with us to create actionable items on which they can move forward with. If you want to move fast and work with someone who "gets it", then Chris is the right person for you.
Goli Team

Analyze Agency ‘s was very good, but more importantly, we had a ton of follow-up work and questions, and the team made themselves available at odd hours and were very responsive throughout. They even spotted significant issues that were driving us nuts in our raw data.
Framer Team

